エントロピーとはいっても高校化学で習った熱力学におけるエントロピーではありません。
機械学習(ランダムフォレストなど)の解説を見ているとでてくるアレです。
でも、エントロピーに関する説明をウィキペディアで読んだけどわからなかった、そんなことはありませんか?
それでは、ウィキペディアでの説明をみてみましょう。
情報理論においてエントロピーは確率変数が持つ情報の量を表す尺度で、それゆえ情報量とも呼ばれる。
確率変数Xに対し、XのエントロピーH(X)は
(ここでPiはX = iとなる確率)
で定義されており、これは統計力学におけるエントロピーと定数倍を除いて一致する。この定式化を行ったのはクロード・シャノンである。
これは単なる数式上の一致ではなく、統計力学的な現象に対して情報理論的な意味づけを与える事ができることを示唆する。
情報量は確率変数Xが数多くの値をとればとるほど大きくなる傾向があり、したがって情報量はXの取る値の「乱雑さ」を表す尺度であると再解釈できる。
よって情報量の概念は、原子や分子の「乱雑さの尺度」を表す統計力学のエントロピーと概念的にも一致する。
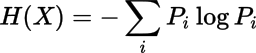
うーん、ちょっとピンときませんね。^^;
「確率変数が持つ情報の量を表す尺度」とか言われても理解できないですよ~
ただ、一行目に重要なことが書いてあります。
だそうです。
エントロピーは情報量とも呼ばれている、らしいです。
と考えてよいということですね。
エントロピーの計算式を考える前に、まず情報量とは一体何者なのかを考えてみましょう。
私達も「情報量」という言葉は日常的によく使います。
例えば、「このブログは情報量が多い」などと使います。
「情報量が多い」という言葉のニュアンスとしては、単に記事の文字が多いというより、記事内容が充実している、
といったことを指しているように思います。
例えば、次のような2つのブログ記事があったとします。
記事B: 朝から関東の広い範囲で雪が降った。北日本から関東の上空に寒気が入った影響のためだ。都心の最低気温は2度だった。
あなたは、どちらが情報量が多いと感じるでしょうか。
記事Aは100文もありますが、得られる情報は「今日は雪だった」ということだけです。
一方、記事Bは少なくとも3つの情報が含まれています。「雪が降ったという事実」、「雪が降った原因」、「最低気温」といった情報が含まれています。
直感的には情報量は、記事B>記事Aだといえるでしょう。
このような問題を感覚的ではなく、数学的に扱おうというのが情報理論(Information theory)という学問です。
エントロピー(情報エントロピー)は、情報理論の概念です。
情報理論の基本的な応用としては、ZIP、MP3などがあります。
とても身近な技術ということがお分かり頂けるかと思います。
さて、冒頭のウィキペディアの説明に戻りましょう。
さきほど直感的に情報量は、記事B>記事Aであると書きました。
であれば、エントロピーも、記事B>記事Aの関係が成り立つはずです。
それをこれから確認してみましょう。
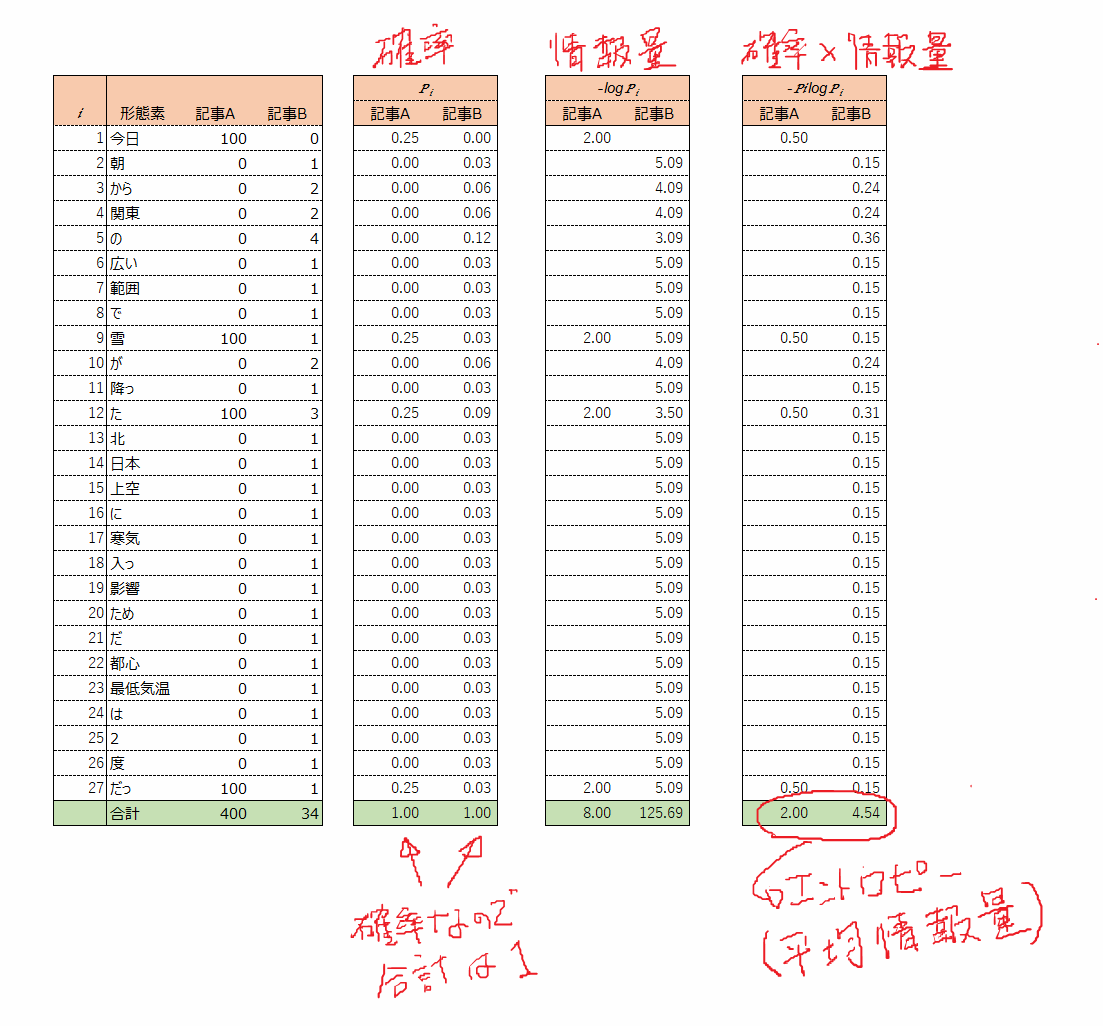
先程の記事A、Bを確率的に扱うために、形態素に分解してみます。
/(スラッシュ)は区切り位置がわかりやすいように記載しています。
記事B: 朝/から/関東/の/広い/範囲/で/雪/が/降っ/た/。/北/日本/から/関東/の/上空/に/寒気/が/入っ/た/影響/の/ため/だ/。/都心/の/最低気温/は/2/度/だっ/た/。/
続けて記事A、Bの形態素を数えて表にしてみます。
そして、先ほどのエントロピーの計算式に当てはめて、EXCELで計算しちゃいましょう。
結果は、記事Aが2.00、記事Bが5.45となり。
予想どおり、記事Bのほうがエントロピー(情報量)が高いという結果になりました。
計算式の解説については、また別日に追記したいと思います。
機械学習の概説が中心になりますが、基本的なことから勉強するなら以下の本がおすすめです。
■アマゾンで買うならこちら
■楽天で買うならこちら
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/0eef6d8a.52d86349.0eef6d8b.8a5cabfd/?me_id=1213310&item_id=17871540&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F0214%2F9784627880214.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F0214%2F9784627880214.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
事例+演習で学ぶ機械学習 [ 速水悟 ]
|