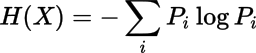make、configureを叩く必要はなく、apt-getで簡単にインストールできる。
mecab-pythonもapt-getでインストールすることはできるが、今回はanaconda環境に入れたかったのでpipでインストールした。
$sudo apt-get install mecab libmecab-dev mecab-ipadic $sudo apt-get install mecab-ipadic-utf8 $pip install mecab-python
make、configureを叩く必要はなく、apt-getで簡単にインストールできる。
mecab-pythonもapt-getでインストールすることはできるが、今回はanaconda環境に入れたかったのでpipでインストールした。
$sudo apt-get install mecab libmecab-dev mecab-ipadic $sudo apt-get install mecab-ipadic-utf8 $pip install mecab-python
京都大学の 日本語構文・格・照応解析ツールのKNPをUbuntuにインストールしたときのメモです。
途中でmakeがすんなり行かなかったりしたので、メモを残しておきます。
環境は以下のとおりです。
| OS | Ubuntu 16.04 LTS |
| 形態素解析器 | JUMAN Ver.7.01 or JUMAN++ Ver.1.01 |
| その他パッケージ | CRF++ 0.58、zlib |
ではインストールの手順です。
今回はトラブルのメモが主ですので、手順は適当に省略しています。
JUMAN Ver.7.01 or JUMAN++ Ver.1.01のインストールについてはマニュアルやウェブを参照してください。
■CRF++のインストール
https://taku910.github.io/crfpp/#download
から
CRF++-0.58.tar.gz
をダウンロードして適当な場所に展開。
手順はいつもどおり、configure→make installで。
■zlibのインストール
■KNPのインストール
これもいつもどおり、configure→make installで。
ところがリンクの最中に以下のエラーがでた。
/home/******/workspace/knp-4.16/distsim/.libs/libdistsim.a(distsim.o): In function `Dbm::decompress_string[abi:cxx11](unsigned char*, int)’:
/home/******/workspace/knp-4.16/distsim/dbm.h:220: undefined reference to `inflateInit_’
/home/******/workspace/knp-4.16/distsim/dbm.h:230: undefined reference to `inflate’
/home/******/workspace/knp-4.16/distsim/dbm.h:235: undefined reference to `inflateEnd’
collect2: error: ld returned 1 exit status
Makefile:433: ターゲット ‘knp’ のレシピで失敗しました
undefined referenceになっているのは、どうやらzlibの関数のようです。
リンク時にライブラリが指定されていないようなので、Makefileに追加してやる。
MakefileのKNP_LIBSに「-lzlib」を追加
再度、makeしたら通った。
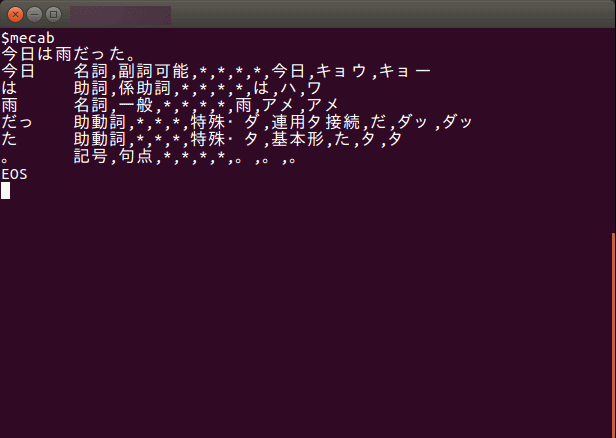
次のように実行できたら成功だ。
今日、──┐
ラーメンを──┤
食べた。
EOS
自然言語処理の入門書としては以下の書籍がおすすめです。
エントロピーとはいっても高校化学で習った熱力学におけるエントロピーではありません。
機械学習(ランダムフォレストなど)の解説を見ているとでてくるアレです。
でも、エントロピーに関する説明をウィキペディアで読んだけどわからなかった、そんなことはありませんか?
それでは、ウィキペディアでの説明をみてみましょう。
情報理論においてエントロピーは確率変数が持つ情報の量を表す尺度で、それゆえ情報量とも呼ばれる。
確率変数Xに対し、XのエントロピーH(X)は
(ここでPiはX = iとなる確率)
で定義されており、これは統計力学におけるエントロピーと定数倍を除いて一致する。この定式化を行ったのはクロード・シャノンである。
これは単なる数式上の一致ではなく、統計力学的な現象に対して情報理論的な意味づけを与える事ができることを示唆する。
情報量は確率変数Xが数多くの値をとればとるほど大きくなる傾向があり、したがって情報量はXの取る値の「乱雑さ」を表す尺度であると再解釈できる。
よって情報量の概念は、原子や分子の「乱雑さの尺度」を表す統計力学のエントロピーと概念的にも一致する。
うーん、ちょっとピンときませんね。^^;
「確率変数が持つ情報の量を表す尺度」とか言われても理解できないですよ~
ただ、一行目に重要なことが書いてあります。
だそうです。
エントロピーは情報量とも呼ばれている、らしいです。
と考えてよいということですね。
エントロピーの計算式を考える前に、まず情報量とは一体何者なのかを考えてみましょう。
私達も「情報量」という言葉は日常的によく使います。
例えば、「このブログは情報量が多い」などと使います。
「情報量が多い」という言葉のニュアンスとしては、単に記事の文字が多いというより、記事内容が充実している、
といったことを指しているように思います。
例えば、次のような2つのブログ記事があったとします。
あなたは、どちらが情報量が多いと感じるでしょうか。
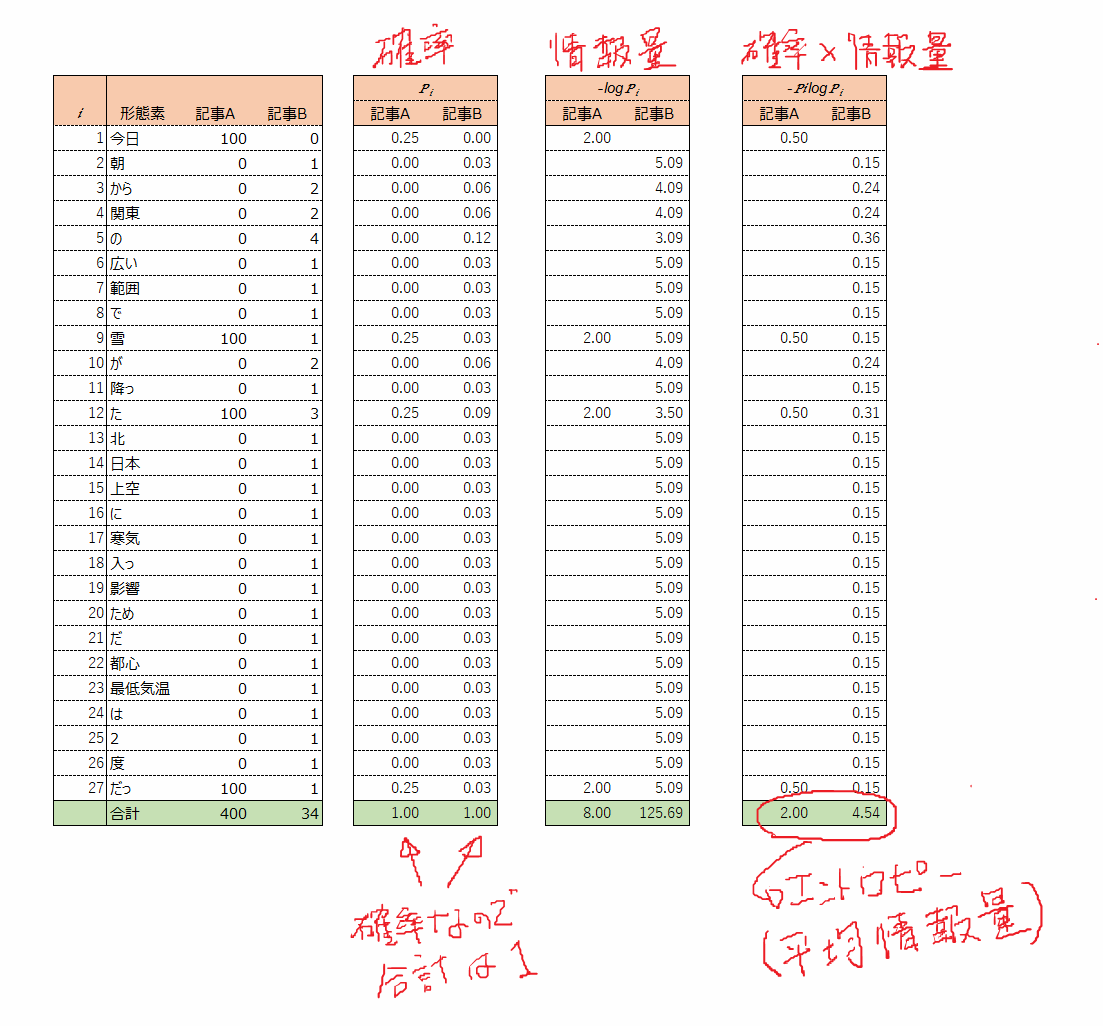
記事Aは100文もありますが、得られる情報は「今日は雪だった」ということだけです。
一方、記事Bは少なくとも3つの情報が含まれています。「雪が降ったという事実」、「雪が降った原因」、「最低気温」といった情報が含まれています。
直感的には情報量は、記事B>記事Aだといえるでしょう。
このような問題を感覚的ではなく、数学的に扱おうというのが情報理論(Information theory)という学問です。
エントロピー(情報エントロピー)は、情報理論の概念です。
情報理論の基本的な応用としては、ZIP、MP3などがあります。
とても身近な技術ということがお分かり頂けるかと思います。
さて、冒頭のウィキペディアの説明に戻りましょう。
さきほど直感的に情報量は、記事B>記事Aであると書きました。
であれば、エントロピーも、記事B>記事Aの関係が成り立つはずです。
それをこれから確認してみましょう。
先程の記事A、Bを確率的に扱うために、形態素に分解してみます。
/(スラッシュ)は区切り位置がわかりやすいように記載しています。
続けて記事A、Bの形態素を数えて表にしてみます。
そして、先ほどのエントロピーの計算式に当てはめて、EXCELで計算しちゃいましょう。
結果は、記事Aが2.00、記事Bが5.45となり。
予想どおり、記事Bのほうがエントロピー(情報量)が高いという結果になりました。
計算式の解説については、また別日に追記したいと思います。
機械学習の概説が中心になりますが、基本的なことから勉強するなら以下の本がおすすめです。
■アマゾンで買うならこちら
■楽天で買うならこちら
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/0eef6d8a.52d86349.0eef6d8b.8a5cabfd/?me_id=1213310&item_id=17871540&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F0214%2F9784627880214.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F0214%2F9784627880214.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
事例+演習で学ぶ機械学習 [ 速水悟 ]
|
事前準備として次のソフトをインストールしておきます。
・gitクライアント
・word2vec
word2vecをWindowsにインストールする方法は、Windowsにword2vecをインストールする方法を参照してください。
gitからファイルをダウンロードします。
git clone https://github.com/klb3713/sentence2vec
ダウンロードされるファイルは次のとおり。
README.md demo.py matutils.py sent.txt test.txt utils.py voidptr.h word2vec.py word2vec_inner.pyx
sent.txtの内容は次のとおり。(1行に1文形式)
Harbin Institute of Technology (HIT) was founded in 1920. After nearly 100 years, HIT has developed into a large nationally renowned multi-disciplinary university with science, engineering and research as its core. HIT is consistently on the forefront in making innovations in research. For years, HIT has continued to undertake large-scale and highly sophisticated national projects. HIT students study humanities and social sciences along with basic engineering and science courses for a strong comprehensive base. HIT is famous for its original style of schooling: 'Being strict in qualifications for graduates; making every endeavor in educating students.' HIT has remained an international university since its foundation. Courses at HIT used to be conducted exclusively in Russian and Japanese. Today, all the faculty, students and staff of HIT, are dedicating, with full confidence
test.txtは次のような内容。7行です。
Harbin Institute of Technology (HIT) was founded in 1920. From its beginning, HIT has received preferential support from the central government. In 1954, the Ministry of Higher Education designated, for the first time, six national key universities. HIT was the only one of the six outside of Beijing. In 1984, HIT again found its way onto the list of 15 national key universities to receive special support. In 1996, HIT was among the first group of universities to be included in Project 211. This project targets 100 institutions of higher education in China to receive preferential support for development in order to become world-class universities in the 21st century. In 1999, HIT was listed as one of the top nine key universities in China. This distinction provided HIT with the opportunity to develop into a highly-competitive first-rate university with the assistance of the Ministry of Education and the Heilongjiang Provincial Government. After nearly 100 years, HIT has developed into a large nationally renowned multi-disciplinary university with science, engineering and research as its core. We have established our own unique programs related to the field of astronautics that are unparalled anywhere in China. We have broadened our established disciplinary programs by utilizing a cross- disciplinary curriculum and as such have formed a comparatively full disciplinary system that consists of key, emerging and supporting programs. HIT now has 21 schools/departments, including 73 undergraduate programs, 147 masters' programs, 81 doctoral programs, 18 post-doctoral research stations, 18 national key disciplines, and 32 national & provincial (ministerial) key labs. The university employs 2,944 full-time teachers, among which 884are professors, 1,102 are associate professors, including 22 academicians of the Chinese Academy of Sciences and the Chinese Academy of Engineering. At present, there are 42,695 full-time students including 25,035 undergraduates, 11,794 master degree candidates and 4,387 doctorial degree candidates. We also added the Shenzhen Graduate School and Weihai Campus to the main campus in Harbin (including the Research Academy of Science and Technology and Research Academy of Industrial Technology), forming a pattern of 'one university, three campuses'. HIT is consistently on the forefront in making innovations in research. For years, HIT has continued to undertake large-scale and highly sophisticated national projects. HIT's ability for scientific research has always been among the strongest in all universities in China. In 2007, HIT funds for scientific research reached 1.1billion RMB. In the comprehensive 10-year evaluation of the '863'project, HIT scientific research programs ranked second among all universities in China. HIT has been making great contributions to China's hi-tech research by creating many new inventions in scientific research fields such as China's first simulation computer, the first intelligent chess-playing computer, the first arc-welding robots, the first world advanced-level system radar, the first CMOS chip IC card with our own patent, the first giant computer-aided real-time 3-D image construction system, the first microcomputer-operated fiber twiner and the first large-scale tank-head forming machine. The famous 'Shenzhou Series Spaceship Project' received massive assistance from HIT in the field of large-scale land-based space simulation equipment, returning cabin deformation and orthopraxy welding technology, 3-axel simulation experimental platform and fault diagnosis. The micro-satellite 'Testing Satellite No.1', constructed mainly by HIT, was the first fully developed and launched satellite by a Chinese university. The technical advancements on the satellite meet international aerospace standards and mark a new chapter in the history of HIT and China's history of astronautics. HIT students study humanities and social sciences along with basic engineering and science courses for a strong comprehensive base. They go on to learn scientific research methods and laboratory skills which enhance their creativity and innovative abilities. When our students graduate from HIT, they are equipped with strong theoretical knowledge and the ability for practical application. HIT is famous for its original style of schooling: 'Being strict in qualifications for graduates; making every endeavor in educating students.' Our graduates have been warmly welcomed by employers throughout China; more than 100,000 graduates have stepped into society and many have moved up to high-ranking managerial positions and work as specialists in the fields of science and technology, education, and economics. A number of graduates have assumed leadership positions in the CPC and governments at different levels, or become generals of the PLA, academicians of the Chinese Academy of Sciences and the Chinese Academy of Engineering. HIT has remained an international university since its foundation. Courses at HIT used to be conducted exclusively in Russian and Japanese. After the reforming and opening to the outside world, HIT has gained greater weight in the world. So far, we have signed academic cooperation agreements with 126 institutions of higher education in 24 countries such as the United States, the United Kingdom, France, Germany, Japan and Russia. Cooperation and exchanges are carried out between HIT and these universities though exchanging students, faculty and research staff, holding academic conference and cooperating in scientific research. Today, all the faculty, students and staff of HIT, are dedicating, with full confidence, their concerted efforts to advance bravely towards the goal of building HIT into a well-known world-class university.
demo.pyを実行するとモデルファイルが作成されます。
python demo.py
すると以下のファイルが作成されます。
sent.txt.vec test.txt.model test.txt.vec
少し中途半端ですが、本日はここまで。近いうちに使用例を書きたいと思います。
文字列同士のレーベンシュタイン距離(編集距離)を計算してくれるライブラリがあります。
とりあえずインストールしてみました。
pip install python-levenshtein
>>> import Levenshtein
>>> Levenshtein.distance('Levenshtein', 'Lenvinsten')
4
レーベンシュタイン距離(編集距離)は4です。
>>> Levenshtein.distance('ほげほげ', 'ほげほげ')
0
レーベンシュタイン距離(編集距離)は0です。
>>> Levenshtein.distance('ほげほげa', 'ほげほげ')
1
半角文字を1文字追加した場合のレーベンシュタイン距離(編集距離)は1です。
>>> Levenshtein.distance('ほげほげほ', 'ほげほげ')
2
全角文字を1文字追加した場合のレーベンシュタイン距離(編集距離)は2です。
ニコニコ大百科の転送項目 Wikipediaのリダイレクトテーブル
本文抽出のパッケージの中では比較的手軽に使えそうな“python-goose”を試してみました。 インストールは以下の手順でOKでした。 上記手順の3行目“pip install -r requirements.txt”…
本文抽出の手法について探していたところ、CybouzLabsさんのサイトにWebページの本文抽出に関する記事とソースがアップされていましたので参考にさせていただきました。 オリジナルソースはRubyで書かれたものです。 …