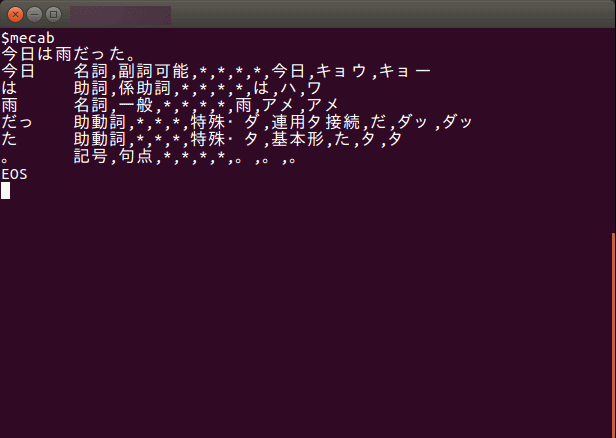
事象
以下のような辞書に格納されたデータ
person_j1 = {“name”: u”山田 太郎”, “gender”: “male”, “age”: 18}
を次のようにurlエンコードした場合があります。
‘gender=male&age=18&name=%E5%B1%B1%E7%94%B0+%E5%A4%AA%E9%83%8E’
このときにurllibのurlencodeを使用すると次のようなエラーが発生する場合があります。
UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 0-1: ordinal not in range(128)
原因
“name”: u”山田 太郎”のようにunicode文字列が含まれているとエラーになります。
実際の例
import urllib
person_e = {"name": "Taro Yamada", "gender": "male", "age": 18}
person_j1 = {"name": u"山田 太郎", "gender": "male", "age": 18} #nameがunicode
person_j2 = {"name": "山田 太郎", "gender": "male", "age": 18} #nameが文字列
urllib.urlencode(person_e) #OK
urllib.urlencode(person_j1) #NG
urllib.urlencode(person_j2) #OK
以下のようにエラーになります。
UnicodeEncodeErrorTraceback (most recent call last)
<ipython-input-38-d6c34797cf92> in <module>()
6
7 urllib.urlencode(person_e) #OK
----> 8 urllib.urlencode(person_j1) #NG
9 urllib.urlencode(person_j2) #OK
10
C:\Anaconda2\lib\urllib.pyc in urlencode(query, doseq)
1341 for k, v in query:
1342 k = quote_plus(str(k))
-> 1343 v = quote_plus(str(v))
1344 l.append(k + '=' + v)
1345 else:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
対処方法
unicode文字列だけ’utf-8’だけエンコードしてやります
数字に対しては.encode(‘utf-8’)できないので、unicode文字列だけencodeしてあげるのがポイントです。
import urllib
person_j1 = {"name": u"山田 太郎", "gender": "male", "age": 18}
person_j1 = dict([k, v.encode('utf-8') if isinstance(v, unicode) else v] for k, v in person_j1.items())
urllib.urlencode(person_j1) #OK
Pythonでディープラーニングを始めるなら以下の本がおすすめです。
アマゾンならこちら
楽天ならこちら
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/159eb138.8feadfa8.159eb139.5e139fb7/?me_id=1251035&item_id=14464736&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fhmvjapan%2Fcabinet%2F7290000%2F7288858.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fhmvjapan%2Fcabinet%2F7290000%2F7288858.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")
【送料無料】 ゼロから作るDeep Learning Pythonで学ぶディープラーニングの理論と実装 / 斎藤康毅 【本】
|

![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/0eef6d8a.52d86349.0eef6d8b.8a5cabfd/?me_id=1213310&item_id=18172266&m=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F7584%2F9784873117584.jpg%3F_ex%3D80x80&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F7584%2F9784873117584.jpg%3F_ex%3D128x128&s=128x128&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")